No artigo de hoje iremos aprender um pouco de PL/SQL, a linguagem procedural da Oracle que estende comandos da linguagem SQL. Para entender melhor o que é PL/SQL, sugiro a leitura do artigo PL/SQL: o que é e quando usar?.
Aprenderemos um pouco de PL/SQL através de um exemplo que demonstrará 5 formas diferentes de se fazer a mesma coisa: atualizar salários de empregados, aplicando as algumas regras de negócios. O exemplo será demonstrado através de um bloco PL/SQL, subdividido em 5 partes, onde cada parte utilizará um recurso específico e apresentará uma performance diferenciada. O objetivo principal deste artigo é demonstrar a melhor forma de se resolver um problema (atualizar os salários dos empregados), considerando a performance de execução de cada parte do bloco de código.
Agora vamos entender melhor o problema. Nós temos que atualizar os salários de todos os empregados de uma organização, de acordo com as seguintes regras:
1- Se o cargo do empregado é 'AD_PRES', devemos dar um aumento de 100%;
2- Se o cargo do empregado é 'AD_VP', devemos dar um aumento de 50%;
3- Se o cargo do empregado é 'IT_PROG', devemos dar um aumento de 25%;
4- Se o cargo do empregado é 'SA_REP', devemos dar um aumento de 20%;
5- Se o cargo do empregado é 'AC_MGR', devemos dar um aumento de 15%.
Iremos implementar a solução através das seguintes formas:
1- Se o cargo do empregado é 'AD_PRES', devemos dar um aumento de 100%;
2- Se o cargo do empregado é 'AD_VP', devemos dar um aumento de 50%;
3- Se o cargo do empregado é 'IT_PROG', devemos dar um aumento de 25%;
4- Se o cargo do empregado é 'SA_REP', devemos dar um aumento de 20%;
5- Se o cargo do empregado é 'AC_MGR', devemos dar um aumento de 15%.
Iremos implementar a solução através das seguintes formas:
1- Um bloco de código que utiliza somente SQL, atualizando os salários dos empregados através de 5 comandos UPDATE, com cláusulas WHERE para filtrar/atualizar cada cargo. Cada comando atualizará os salários de todos os empregados de um determinado cargo;
2- Um bloco de código que preenche um CURSOR com os dados de todos os empregados dos 5 cargos necessários e que atualiza os salários de todos os empregados destes cargos, percorrendo através de um loop todos os registros do cursor, atualizando 1 registro por vez.
A atualização é efetuada da seguinte forma: lê-se um registro de empregado no cursor e executa-se em seguida um comando UPDATE para atualizar o empregado com o mesmo identificador (coluna EMPLOYEE_ID da tabela HR.EMP) da linha atual do CURSOR.
3- Um bloco de código que preenche um CURSOR com os dados de todos os empregados dos 5 cargos necessários e que atualiza os salários de todos empregados destes cargos, percorrendo através de um loop todos os registros do cursor, atualizando 1 registro por vez.
A atualização é efetuada da seguinte forma: lê-se um registro de empregado no cursor e executa-se em seguida um comando UPDATE para atualizar o empregado com o mesmo ROWID (referenciado implícitamente através da cláusula CURRENT OF) da linha atual do CURSOR.
4- Um bloco de código que preenche um CURSOR com os dados de todos os empregados dos 5 cargos necessários e que preenche uma collection NESTED TABLE com estes mesmos dados. A atualização é feita através de um loop que utiliza BULK COLLECT de 200 registros do cursor por vez, preenche com estes registros um objeto NESTED TABLE, efetuando a atualização de 1 empregado por vez.
4- Um bloco de código que preenche um CURSOR com os dados de todos os empregados dos 5 cargos necessários e que preenche uma collection NESTED TABLE com estes mesmos dados. A atualização é feita através de um loop que utiliza BULK COLLECT de 200 registros do cursor por vez, preenche com estes registros um objeto NESTED TABLE, efetuando a atualização de 1 empregado por vez.
A atualização é feita da seguinte forma: lê-se um registro de empregado na NESTED TABLE e executa-se em seguida um comando UPDATE para atualizar o empregado com o mesmo identificador (coluna EMPLOYEE_ID).
5- Um bloco de código semelhante ao bloco do item 3, mas que substitui os IF's pela instrução CASE.
Segue abaixo um roteiro passo-a-passo que demonstra como executar as 5 soluções propostas acima. Execute-o e veja os resultados:
5- Um bloco de código semelhante ao bloco do item 3, mas que substitui os IF's pela instrução CASE.
Segue abaixo um roteiro passo-a-passo que demonstra como executar as 5 soluções propostas acima. Execute-o e veja os resultados:
------------------------------------------------------------------------
PASSO-A-PASSO
------------------------------------------------------------------------
--------------------------------------------------------------------------
Para iniciar o passo-a-passo abaixo, é necessário:
1- Conectar-se previamente no Banco de Dados (BD) desejado, através do SQL Plus ou
outra ferramenta compatível, com um usuário que tenha privilégios administrativos ou com o usuário HR.
2- Ter instalado no BD o schema HR. Se o BD não tiver o schema HR e você precisar de orientação para
fazer a sua instalação, leia o artigo Instalando o schema de exemplo HR.
--------------------------------------------------------------------------
Passo 1- Criando a tabela HR.EMP:
Para não alterar os dados originais das tabelas do schema HR, iremos criar uma nova tabela chamada HR.EMP, cópia da tabela HR.EMPLOYEES:
SQL> create table hr.emp as select * from hr.employees;
Passo 2- Populando a tabela HR.EMP:
begin
for i in 200..10000
loop
insert into hr.emp (employee_id, first_name, last_name, email, phone_number, hire_date, job_id, salary, commission_pct, manager_id, department_id)
values (i,'name ' || to_char(i), 'lname ' || to_char(i), '@', null, sysdate -100, 'IT_PROG', 2 * i, null, null, null);
end loop;
for i in 10001..11000
loop
insert into hr.emp (employee_id, first_name, last_name, email, phone_number, hire_date, job_id, salary, commission_pct, manager_id, department_id)
values (i,'name ' || to_char(i), 'lname ' || to_char(i), '@', null, sysdate -100, 'SA_REP', 2 * i, null, null, null);
end loop;
for i in 11001..20000
loop
insert into hr.emp (employee_id, first_name, last_name, email, phone_number, hire_date, job_id, salary, commission_pct, manager_id, department_id)
values (i,'name ' || to_char(i), 'lname ' || to_char(i), '@', null, sysdate -100, 'AC_MGR', 2 * i, null, null, null);
end loop;
for i in 20001..21000
loop
insert into hr.emp (employee_id, first_name, last_name, email, phone_number, hire_date, job_id, salary, commission_pct, manager_id, department_id)
values (i,'name ' || to_char(i), 'lname ' || to_char(i), '@', null, sysdate -100, 'AD_VP', 2 * i, null, null, null);
end loop;
for i in 21001..22000
loop
insert into hr.emp (employee_id, first_name, last_name, email, phone_number, hire_date, job_id, salary, commission_pct, manager_id, department_id)
values (i,'name ' || to_char(i), 'lname ' || to_char(i), '@', null, sysdate -100, 'AD_PRESS', 2 * i, null, null, null);
end loop;
COMMIT;
end;
Resultado:
A tabela deverá ter aprox. 21.908 registros.
Passo 3- Atualizando os salários dos empregados:
Execute o script abaixo para atualizar os salários e verifique o tempo de execucao que sera retornado:
set serveroutput on
--1: SOMENTE SQL
DECLARE
CURSOR CR IS
SELECT *
FROM HR.EMP
WHERE JOB_ID IN ('AD_PRES','AD_VP','IT_PROG','SA_REP','AC_MGR') FOR UPDATE;
TYPE emp_type IS TABLE OF hr.emp%ROWTYPE;
emp_table emp_type;
BEGIN
dbms_output.put_line('BLOCO 1 (SOMENTE SQL) - Hora início: ' || to_char(systimestamp, 'dd/mm/yyyy hh24:mi:ss'));
UPDATE HR.EMP
SET SALARY = SALARY * 2
WHERE JOB_ID = 'AD_PRES';
UPDATE HR.EMP
SET SALARY = SALARY * 1.5
WHERE JOB_ID = 'AD_VP';
UPDATE HR.EMP
SET SALARY = SALARY * 1.25
WHERE JOB_ID = 'IT_PROG';
UPDATE HR.EMP
SET SALARY = SALARY * 1.2
WHERE JOB_ID = 'SA_REP';
UPDATE HR.EMP
SET SALARY = SALARY * 1.15
WHERE JOB_ID = 'AC_MGR';
dbms_output.put_line('BLOCO 1 (SOMENTE SQL) - Hora fim: ' || to_char(systimestamp, 'dd/mm/yyyy hh24:mi:ss'));
rollback;
--2: pl/sql com cursor e update sem when current of
dbms_output.put_line('BLOCO 2 (PL/SQL c/ CURSOR e update sem when current of) - Hora início: ' || to_char(systimestamp, 'dd/mm/yyyy hh24:mi:ss'));
FOR r in (SELECT *
FROM HR.EMP
WHERE JOB_ID IN ('AD_PRES','AD_VP','IT_PROG','SA_REP','AC_MGR' ))
LOOP
IF r.JOB_ID = 'AD_PRES' THEN
UPDATE HR.EMP
SET SALARY = SALARY * 2
WHERE EMPLOYEE_ID = r.EMPLOYEE_ID;
ELSIF r.JOB_ID = 'AD_VP' THEN
UPDATE HR.EMP
SET SALARY = SALARY * 1.5
WHERE EMPLOYEE_ID = r.EMPLOYEE_ID;
ELSIF r.JOB_ID = 'IT_PROG' THEN
UPDATE HR.EMP
SET SALARY = SALARY * 1.25
WHERE EMPLOYEE_ID = r.EMPLOYEE_ID;
ELSIF r.JOB_ID = 'SA_REP' THEN
UPDATE HR.EMP
SET SALARY = SALARY * 1.2
WHERE EMPLOYEE_ID = r.EMPLOYEE_ID;
ELSIF r.JOB_ID = 'AC_MGR' THEN
UPDATE HR.EMP
SET SALARY = SALARY * 1.15
WHERE EMPLOYEE_ID = r.EMPLOYEE_ID;
END IF;
END LOOP;
dbms_output.put_line('BLOCO 2 (PL/SQL c/ CURSOR e update sem when current of) - Hora fim: ' || to_char(systimestamp, 'dd/mm/yyyy hh24:mi:ss'));
rollback;
--3: pl/sql com cursor e update com when current of
dbms_output.put_line('BLOCO 3 (PL/SQL c/ CURSOR e update com when current of) - Hora início: ' || to_char(systimestamp, 'dd/mm/yyyy hh24:mi:ss'));
FOR r in CR
LOOP
IF r.JOB_ID = 'AD_PRES' THEN
UPDATE HR.EMP
SET SALARY = SALARY * 2
WHERE CURRENT OF CR;
ELSIF r.JOB_ID = 'AD_VP' THEN
UPDATE HR.EMP
SET SALARY = SALARY * 1.5
WHERE CURRENT OF CR;
ELSIF r.JOB_ID = 'IT_PROG' THEN
UPDATE HR.EMP
SET SALARY = SALARY * 1.25
WHERE CURRENT OF CR;
ELSIF r.JOB_ID = 'SA_REP' THEN
UPDATE HR.EMP
SET SALARY = SALARY * 1.2
WHERE CURRENT OF CR;
ELSIF r.JOB_ID = 'AC_MGR' THEN
UPDATE HR.EMP
SET SALARY = SALARY * 1.15
WHERE CURRENT OF CR;
END IF;
END LOOP;
dbms_output.put_line('BLOCO 3 (PL/SQL c/ CURSOR e update com when current of) - Hora fim: ' || to_char(systimestamp, 'dd/mm/yyyy hh24:mi:ss'));
ROLLBACK;
--4: pl/sql com collection nested table e BULK COLLECT
dbms_output.put_line('BLOCO 4 (PL/SQL c/ collection com nested table e BULK COLLECT) - Hora início: ' || to_char(systimestamp, 'dd/mm/yyyy hh24:mi:ss'));
OPEN CR;
LOOP
FETCH CR BULK COLLECT INTO emp_table LIMIT 200;
FOR i in 1..emp_table.count()
LOOP
IF emp_table(i).JOB_ID = 'AD_PRES' THEN
UPDATE HR.EMP
SET SALARY = SALARY * 2
WHERE EMPLOYEE_ID = emp_table(i).EMPLOYEE_ID;
ELSIF emp_table(i).JOB_ID = 'AD_VP' THEN
UPDATE HR.EMP
SET SALARY = SALARY * 1.5
WHERE EMPLOYEE_ID = emp_table(i).EMPLOYEE_ID;
ELSIF emp_table(i).JOB_ID = 'IT_PROG' THEN
UPDATE HR.EMP
SET SALARY = SALARY * 1.25
WHERE EMPLOYEE_ID = emp_table(i).EMPLOYEE_ID;
ELSIF emp_table(i).JOB_ID = 'SA_REP' THEN
UPDATE HR.EMP
SET SALARY = SALARY * 1.2
WHERE EMPLOYEE_ID = emp_table(i).EMPLOYEE_ID;
ELSIF emp_table(i).JOB_ID = 'AC_MGR' THEN
UPDATE HR.EMP
SET SALARY = SALARY * 1.15
WHERE EMPLOYEE_ID = emp_table(i).EMPLOYEE_ID;
END IF;
END LOOP;
EXIT WHEN CR%NOTFOUND;
END LOOP;
CLOSE CR;
dbms_output.put_line('BLOCO 4 (PL/SQL c/ collection com nested table e BULK COLLECT) - Hora fim: ' || to_char(systimestamp, 'dd/mm/yyyy hh24:mi:ss'));
ROLLBACK;
--5: pl/sql com cursor e update com when current of + condicional case (ao inves de if)
dbms_output.put_line('BLOCO 5 (pl/sql com cursor e update com when current of + condicional case (ao inves de if)) - Hora início: ' || to_char(systimestamp, 'dd/mm/yyyy hh24:mi:ss'));
FOR r in CR
LOOP
UPDATE HR.EMP
SET SALARY = CASE r.JOB_ID
WHEN 'AD_PRES' THEN SALARY * 2
WHEN 'AD_VP' THEN SALARY * 1.5
WHEN 'IT_PROG' THEN SALARY * 1.25
WHEN 'SA_REP' THEN SALARY * 1.2
WHEN 'AC_MGR' THEN SALARY * 1.15
END
WHERE CURRENT OF CR;
END LOOP;
dbms_output.put_line('BLOCO 5 (pl/sql com cursor e update com when current of + condicional case (ao inves de if)) - Hora fim: ' || to_char(systimestamp, 'dd/mm/yyyy hh24:mi:ss'));
ROLLBACK;
END;
 |
| Imagem 01 - Parte do bloco PL/SQL executado acima |
RESULTADOS FINAIS:
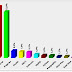
Nos testes que eu fiz, obtive os seguintes tempos de execução de cada bloco PL/SQL:
- BLOCO 1 (somente SQL): 1s
- BLOCO 2 (PL/SQL c/ CURSOR e update sem when current of): 151s
- BLOCO 3 (PL/SQL c/ CURSOR e update com when current of): 4s
- BLOCO 4 (PL/SQL c/ collection nested table e BULK COLLECT): 128s
- BLOCO 5 (PL/SQL CURSOR e update com when current of + case (ao inves de if)): 4s
COMENTÁRIOS FINAIS:
Para resolver o problema deste artigo, o BLOCO 1 utilizando SQL puro (sem interação com PL/SQL) para efetuar as atualizações foi muito mais eficiente, apresentando um desempenho 400% melhor que o 2º bloco mais eficiente (BLOCOS 3 e 5). SQL puro é sempre mais eficiente do que utilizar um cursor ou uma collection. De todo, modo, nem sempre é possível resolver o problema com sql puro, portanto, nestes casos, teremos que usar cursores ou collections. Ambos tem suas vantagens e desvantagens. Collections são normalmente uma boa opção para efetuar cargas de dados em massa (bulk binding), mas é necessário saber escrever código adequado para essa finalidade e isso eu não demonstrei aqui. Cursores normalmente são uma boa opção para economizar memória do SGBD. No código deste artigo, o uso de cursores foi mais rápido que o uso de collections, mas em muitos cenários, o inverso pode acontecer! Mais detalhes sobre cursores, collections e bulk binding eu deixo para explicar nos treinamentos FABIOPRADO.NET de PL/SQL (presenciais ou vídeoaulas).
Para resolver o problema deste artigo, o BLOCO 1 utilizando SQL puro (sem interação com PL/SQL) para efetuar as atualizações foi muito mais eficiente, apresentando um desempenho 400% melhor que o 2º bloco mais eficiente (BLOCOS 3 e 5). SQL puro é sempre mais eficiente do que utilizar um cursor ou uma collection. De todo, modo, nem sempre é possível resolver o problema com sql puro, portanto, nestes casos, teremos que usar cursores ou collections. Ambos tem suas vantagens e desvantagens. Collections são normalmente uma boa opção para efetuar cargas de dados em massa (bulk binding), mas é necessário saber escrever código adequado para essa finalidade e isso eu não demonstrei aqui. Cursores normalmente são uma boa opção para economizar memória do SGBD. No código deste artigo, o uso de cursores foi mais rápido que o uso de collections, mas em muitos cenários, o inverso pode acontecer! Mais detalhes sobre cursores, collections e bulk binding eu deixo para explicar nos treinamentos FABIOPRADO.NET de PL/SQL (presenciais ou vídeoaulas).
Agora vamos analisar cada bloco e responder as seguintes perguntas:
1- Por que o BLOCO 1 executou mais rápido que todos os outros?
R.: O problema dado neste artigo (como atualizar os salários dos empregados) podia ser resolvido com 5 simples instruções SQL, que atualizam múltiplas linhas por vez, sem a necessidade de escrever estruturas de processamento condicionais (Ex.: IF ou CASE) em PL/SQL (que foram escritas nos BLOCOS 2, 3, 4 e 5).
R.: O problema dado neste artigo (como atualizar os salários dos empregados) podia ser resolvido com 5 simples instruções SQL, que atualizam múltiplas linhas por vez, sem a necessidade de escrever estruturas de processamento condicionais (Ex.: IF ou CASE) em PL/SQL (que foram escritas nos BLOCOS 2, 3, 4 e 5).
Há um custo de tempo de execução maior para atualizar as linhas uma a uma (ao invés de múltiplas linhas por vez) e para criar as estruturas de dados adicionais (CURSOR ou COLLECTION Nested Table) em PL/SQL nos blocos 2 ao 5. PL/SQL é uma extensão de SQL, portanto, na maior parte dos casos, PL/SQL só deve ser utilizado quando o conjunto dos comandos SQL, por si só, não são suficientes para resolver o problema.
2- Por que o BLOCO 3 foi mais rápido que o BLOCO 2 se ambos utilizam CURSORES?
R.: No BLOCO 3 a atualização dos salários é feita através de uma ligação (JOIN) entre o cursor e a tabela, que utiliza internamente um ROWID. ROWID é uma pseudo-coluna que existe em todas as tabelas de um Bancos de Dados Oracle, que é utilizada para identificar cada linha em uma tabela. ROWID é o método de acesso mais rápido que existe!
3- Por que o BLOCO 2 foi mais lento que o BLOCO 4 se ambos fazem o mesmo tipo de atualização (efetuando JOIN entre objeto CURSOR ou NESTED TABLE e tabela, através da coluna EMPLOYEE_ID)?
R.: Porque no BLOCO 4 são recuperadas 200 linhas por vez (ao invés de uma por vez no BLOCO 2), via BULK COLLECT, no objeto NESTED TABLE. A atualização com maior número de linhas por vez agiliza o processamento dos dados.
2- Por que o BLOCO 3 foi mais rápido que o BLOCO 2 se ambos utilizam CURSORES?
R.: No BLOCO 3 a atualização dos salários é feita através de uma ligação (JOIN) entre o cursor e a tabela, que utiliza internamente um ROWID. ROWID é uma pseudo-coluna que existe em todas as tabelas de um Bancos de Dados Oracle, que é utilizada para identificar cada linha em uma tabela. ROWID é o método de acesso mais rápido que existe!
3- Por que o BLOCO 2 foi mais lento que o BLOCO 4 se ambos fazem o mesmo tipo de atualização (efetuando JOIN entre objeto CURSOR ou NESTED TABLE e tabela, através da coluna EMPLOYEE_ID)?
R.: Porque no BLOCO 4 são recuperadas 200 linhas por vez (ao invés de uma por vez no BLOCO 2), via BULK COLLECT, no objeto NESTED TABLE. A atualização com maior número de linhas por vez agiliza o processamento dos dados.
4- Por que o BLOCO 5 teve desempenho igual ao BLOCO 3. Não deveriam ter desempenho diferente, pois um utiliza a instrução CASE e o outro a instrução IF?
R.: Em termos de performance, não há diferença ao utilizar a instrução CASE ou IF. O BLOCO 5 (com CASE) só tem a vantagem de ter menos linhas de código, o que facilita a sua legibilidade e manutenções futuras (quando necessário).
Se você não conseguiu entender muita coisa sobre o bloco PL/SQL deste artigo, e quer aprimorar seus conhecimentos, sugiro participar dos treinamentos presenciais ou em videoaulas de PL/SQL.
Bom pessoal, por hoje é só!
[]s





Ola Fabio,
ResponderExcluirque tal incluir um exemplo com o comando DECODE/CASE ?
Entendo que o desempenho sera igual ou melhor que o do 1o. bloco.
saudações,
Sandro.
Sandro, atendi o seu pedido. Já fiz a alteração do artigo incluindo o BLOCO 5, que contém a instrução CASE. O BLOCO 5 teve o mesmo desempenho do BLOCO 3.
ResponderExcluirObrigado pelo comentário.
Fabio tudo bem?
ResponderExcluirMinha dúvida é: por que no primeiro bloco voce declarou um type e um cursor sendo que voce não utilizou nenhum deles nos comandos update ?
Leandro, eu uso o cursor nos blocos 4 e 5, e uso a collection (declarada com type...) no bloco 4.
ExcluirExcelente trabalho Fábio, a explicação da performance é algo que abrilhanta demais o conteúdo exposto. Meus parabéns!!
ResponderExcluirDeividi, obrigado pelo feedback!
Excluir