Olá pessoal,
Estou escrevendo este artigo para compartilhar algo que testei recentemente e que consiste em utilizar paralelismo ao exportar dados via Data Pump. Usar o Data Pump para importar e exportar dados faz parte da rotina quase que diária de um DBA que administra Bancos de Dados Oracle (a partir da versão 10G). Normalmente utilizo o Data Pump para importar e exportar pequenas quantidades de dados, em média 15 GB, que demoram aproximadamente 30 minutos para gerar um dump.
Obs.: Dump é o nome dado a um arquivo que contém os dados que são exportados de um Banco de Dados (BD) e que podem ser posteriormente importados em qualquer BD.
Quando precisamos trabalhar com grandes quantidades de dados, podemos utilizar paralelismo no DataPump para reduzir o tempo de geração dos dumps. Paralelismo, neste caso, consiste em utilizar múltiplos processadores (ou núcleos) no processo de exportação ou importação de dados, para otimizar o tempo destes processos. Como nunca precisei gerar dumps muito grandes e com muita urgência, sempre utilizei o Data Pump sem utilizar recursos de paralelismo.
Visando me preparar para uma eventual e futura necessidade, resolvi fazer alguns testes para verificar o ganho de performance ao exportar dados com múltiplos processadores e vou compartilhar essa experiência com vocês. Um detalhe muito importante é que ao utilizar múltiplos processadores neste processo você só terá melhor desempenho se a exportação gerar múltiplos arquivos de dump. Para gerar múltiplos arquivos com o utilitário expdp, é necessário acrescentar no valor do parâmetro DUMPFILE, a variável %u, que permite gerar um nome único para cada parte (arquivos individuais) do dump, que são criadas por cada processador configurado através do parâmetro PARALLEL. Sem %u um único arquivo de dump é gerado e ao invés de ganhar desempenho, a exportação irá demorar mais. Veremos isso em detalhes adiante.
Exportando dados via Data Pump com paralelismo
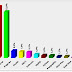
Os testes que vou apresentar abaixo foram realizados com diversas configurações de paralelismo, para exportar via Data Pump, 2 GB de dados, em uma máquina que possui o equivalente a 8 processadores. Os testes em detalhes podem ser conferidos na Figura 1. Abaixo vou comentar apenas sobre o teste em que não usei paralelismo e sobre o teste que obteve o melhor desempenho:
Teste 1: Gerando dump sem paralelismo:
expdp system/senha schemas=TESTE directory=DP dumpfile=teste_1.dmp logfile=exp_teste_1.log
Tempo de execução : 3min34s
Teste 2: Gerando dump com 4 processadores (múltiplos arquivos):
expdp system/senha schemas=TESTE directory=DP PARALLEL=4 dumpfile=teste_4_%U.dmp logfile=exp_teste_4.log
Tempo de execução: 1min47s
 |
| Figura 1 - Testes de desempenho exportando dados via Data Pump |
CONCLUSÃO
Ao utilizar múltiplos processadores (quando a máquina possui mais de um processador), conforme testes apresentados neste artigo, pudemos verificar que a gente pode otimizar o tempo de geração de dumps via Data Pump.
O melhor tempo obtido nos testes, em comparação ao teste em que não utilizei paralelismo, foi quando utilizei metade dos processadores disponíveis na máquina (4 processadores). Nesse teste consegui obter o mesmo resultado, em exatamente metade do tempo. Se você trabalha com VLDBs e precisa reduzir o tempo de geração de seus dumps (que podem durar muitas horas), esta aí um valioso recurso: paralelismo no DATAPUMP!
Para aqueles que buscam mais dicas sobre como otimizar exports/imports via Datapump, sugiro também a leitura do artigo Datapump - some tips.
Por hoje é só!
Até o próximo artigo!
[]s





Muito bom artigo Fabio, só me tira uma dúvida.
ResponderExcluirAcima você salientou que o ganho de desempenho só seria obtido se utilizássemos múltiplos arquivos de dump e disse que teríamos de utilizar a variável %u.
Mas no exemplo você não utiliza essa variável. Você pode explicar melhor essa questão?
Vinicius, nos testes eu utilizei sim, no artigo é que eu esqueci de colocar %U. Já fiz a correção. Obrigado por avisar!
ExcluirGrande Fábio otimo post.Como sempre acompanho seus posts so tenho a parabenizar mais uma vez.
ResponderExcluirSo uma duvida, no caso da versao Standard não tem essa feature ou estou enganado?
Emerson Martins
DBA Jr
Emerson, vc está certo! A Standard Edition não suporta paralelismo em nada (datapump, backup, queries etc.)
Excluir[]s
Fábio, pelo que entendi, se eu utilizar o parametro PARALLEL=2 irá gerar 02 arquivos de dump com nomes únicos devido ao '%u'. A minha dúvida é de como seria feita a importação?
ResponderExcluirExcelente post. Parabéns.
Fernando Almeida.
Boa pergunta Fernando. Para fazer o import é só referenciar o nome do arquivo do mesmo do modo que ele foi criado (incluindo %U).
ExcluirExemplo:
impdp system/senha schemas=TESTE directory=DP PARALLEL=2 dumpfile=teste_2_%U.dmp logfile=imp_teste_2.log
[]s
Boa tarde,
ResponderExcluirFabio.
Parabéns pelos Posts e dicas que sempre vem ajudando e muito a todos os DBA's ou aspirantes a função.
Uma duvida até meio boba mas se eu possuo uma licença que utiliza apenas um Processador esse tipo de funcionalidade não iria adiantar, correto?
Obrigado Sandro pelos comentários. É gratificante saber que os artigos estão ajudando bastante gente.
ExcluirQto à sua pergunta, realmente vc não conseguirá usar paralelismo em versões do BD que não permitem o uso deste recurso. Se vc usar, por exemplo, Oracle XE (Express Edition), vc não consegue executar nada em mais que 1 processador.
[]s
Fábio, boa tarde.
ResponderExcluirMuito interessante a estratégia, porém tenho uma dúvida. Observando os recursos do servidor percebo que o CPU não é o gargalo do export, quando é feito a tarefa o processamento fica em 5, 10% do processador. É o banco que aumenta o tempo de resposta.
Acha que mesmo assim a técnica de pararelismo vai trazer resultados?
Alysson, terá ganho sim se você mandar escrever cada arquivo do dump em discos diferentes, ou até mesmo em uma mesma LUN que tenha vários discos. Nos meus testes o que fez ganhar desempenho também não foi o paralelismo de cpu, mas sim a escrita paralelizada, ok?
Excluir[]s