Olá pessoal,
Você sabia que é possível otimizar SELECTs configurando o arraysize no SQL Plus, ou recursos similares em sua linguagem de programação preferida, que utiliza Oracle Database?
Antes de continuar o assunto, precisamos saber primeiro o que é esse tal de arraysize... então vamos lá! Ao configurar o arraysize no SQL Plus você está informando ao Oracle quantas linhas por vez ele irá retornar do Banco de Dados para o cliente. O valor padrão do arraysize é 15 e ele aceita valores entre 1 e 5000. Configurar um valor muito pequeno, como por exemplo: 1; antes de executar um SELECT que irá retornar 5000 linhas, não é um bom negócio, pois o Oracle Client terá que navegar pela rede (round trips) 5000 vezes para trazer o resultado de 1 linha por vez. Então, neste caso, o melhor a ser feito, seria primeiro configurar o arraysize com um valor de 5000, e depois executar o SQL. Desse modo, o Oracle executaria apenas 1 round trip na rede para trazer todos os dados, e seria muito mais performático! Normalmente quanto menos round trips ocorrerem melhor será a performance (essa é também a principal vantagem na utilização de stored procedures para executar longas transações... e explico isso melhor no artigo Otimizando a performance de aplicações com o uso de stored procedures).
Como acabei de comentar, configurar um valor pequeno de arraysize para um resultado "grande" não é bom em termos performance, e o inverso também não! Ao configurar um valor muito grande para o arraysize (no SQL Plus ou através de sua aplicação) irá gastar muita memória e essa alocação de memória extra, talvez desnecessária, tem um custo, que deverá piorar a performance de um SQL que precisa retornar poucas linhas. É importante ressaltar que o desempenho de um arraysize maior depende também das configurações de rede entre o servidor e cliente.
Abaixo irei mostrar os resultados de alguns testes que fiz no SQL Plus alterando o arraysize (com o comando SET ARRAYSIZE N) para diversos valores, antes de executar um simples SELECT na visão DBA_OBJECTS, que retorna 91.828 linhas. Antes de executar os SQLs, habilitei o autotrace traceonly para ver as estatísticas de execução do SQL:
SQL> set autotrace traceonly
SQL> set arraysize 5
SQL> select * from dba_objects;
91828 linhas selecionadas.
Decorrido: 00:00:07.94
Estatística
----------------------------------------------------------
15 recursive calls
0 db block gets
20198 consistent gets
0 physical reads
0 redo size
5368781 bytes sent via SQL*Net to client
202365 bytes received via SQL*Net from client
18367 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
91828 rows processed
Teste 2: Configurando ARRAYSIZE igual a 100 para retornar um resultado "grande"
SQL> set arraysize 100
SQL> /
91828 linhas selecionadas.
Decorrido: 00:00:01.47
Estatística
----------------------------------------------------------
0 recursive calls
0 db block gets
2967 consistent gets
0 physical reads
0 redo size
3868339 bytes sent via SQL*Net to client
10448 bytes received via SQL*Net from client
920 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
91828 rows processed
Teste 3: Configurando ARRAYSIZE igual a 5000 para retornar um resultado "grande"
SQL> set arraysize 5000
SQL> /
91828 linhas selecionadas.
Decorrido: 00:00:00.74
Estatística
----------------------------------------------------------
0 recursive calls
0 db block gets
2073 consistent gets
0 physical reads
0 redo size
3788248 bytes sent via SQL*Net to client
548 bytes received via SQL*Net from client
20 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
91828 rows processed
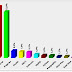
Comparando os 3 testes acima, a gente percebe que há uma grande economia de tempo configurando o arraysize com valor maior para um SQL que retorna um grande resultado, e que a estatística de round trips é proporcional ao tamanho do arraysize. Com arraysize 1 o tempo de resposta foi de 7.94s, já com arraysize 5000 (maior valor permitido), o tempo de resposta caiu para 0.74s, ou seja, tivemos um baita ganho de performance de 1073%.
 |
| Imagem 01 - Round trips caindo com o aumento do tamanho do arraysize |
Não contente com os testes acima, resolvi fazer novos testes para ver o desempenho em uma situação contrária: um SQL que retorna poucas linhas:
Teste 1: Configurando ARRAYSIZE igual a 5000 para retornar 1 linha
SQL> show arraysizearraysize 5000
SQL> select * from dba_objects where rownum =1;
Decorrido: 00:00:00.02
Estatística
----------------------------------------------------------
15 recursive calls
0 db block gets
38 consistent gets
1 physical reads
52 redo size
1228 bytes sent via SQL*Net to client
350 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
Teste 2: Configurando ARRAYSIZE igual a 5 para retornar 1 linha
SQL> set arraysize 5
SQL> /
Decorrido: 00:00:00.01
Estatística
----------------------------------------------------------
15 recursive calls
0 db block gets
13 consistent gets
0 physical reads
0 redo size
1228 bytes sent via SQL*Net to client
350 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
Comparando os 2 últimos testes, a gente percebe que ao retornar poucos dados (1 linha), não há vantagem em se configurar um grande arraysize, pois quando diminuímos o tamanho dele de 5000 para 5 (o que neste caso era mais do que o suficiente), o tempo caiu pela metade, ou seja, de 00:02s para 00.01s. Isso prova a teoria de que não existe uma configuração de arraysize adequada para todo SQL. É importante ressaltar também que em SQLs que retornam poucas linhas, pecar pelo excesso no arraysize não irá te beneficiar.
Aprendeu o conceito? Então utilize-o agora naqueles scripts, que por exemplo, retornam muitos dados e que demoram minutos ou horas para executar, e que você executa no SQL Plus, gravando o resultado em um arquivo de spooling. Pouca gente (tanto DBAs quanto Desenvolvedores) sabe, mas existem recursos que aplicam o mesmo conceito do arraysize nas principais linguagens de programação. Em Java, por exemplo, pesquise sobre o Fetch Size de um Result Set, para que você possa descobrir mais uma forma de otimizar seus SQLs.
Bom pessoal, por hoje é só!
Se tiver qualquer dúvida é só deixar um comentário!
[]s
Aprendeu o conceito? Então utilize-o agora naqueles scripts, que por exemplo, retornam muitos dados e que demoram minutos ou horas para executar, e que você executa no SQL Plus, gravando o resultado em um arquivo de spooling. Pouca gente (tanto DBAs quanto Desenvolvedores) sabe, mas existem recursos que aplicam o mesmo conceito do arraysize nas principais linguagens de programação. Em Java, por exemplo, pesquise sobre o Fetch Size de um Result Set, para que você possa descobrir mais uma forma de otimizar seus SQLs.
Quer aprender mais dicas e técnicas de otimização de SQLs?
Então conheça os nossos treinamentos em videoaulas ou
presenciais/telepresenciais de SQL Tuning
Bom pessoal, por hoje é só!
Se tiver qualquer dúvida é só deixar um comentário!
[]s





Utilizei esta alteração de parâmetro no Sql*plus para extração de dados que retornam mais de 32 milhões de linhas e o tempo caiu de 42 minutos para 7 minutos.
ResponderExcluirLegal João, que valor você configurou para o arraysize?
ExcluirFazendo os testes ficou defino o valor de 1000, neste caso tanto valores maiores ou menores que este davam tempo maior.
ResponderExcluirOk, obrigado pela informação. Ela será útil para outros que lerem este artigo!
Excluir[]s